

Stop the undifferentiated heavy lifting!
In Part 2 of this series we identified the elements of a lean app. But for those elements to be sufficient, the infrastructure on which the application depends needs to start doing a whole lot more than it does today.
What makes an app lean?
Schema based
Where it makes sense, data models (and their evolution) and integrity constraints should be expressed in the form of a standards-based schema, rather than written into application code or deployment instructions.
Another way to say this is that “leanness” also extends to preferring data-centric expressions (BALANCE >= 0) over code (if balance – withdrawal_amount < 0 then throw Exception(withdrawal_amount, …). This is both to ensure that the expression itself is lean (the less there is to read and write, the less there is to get wrong or have to carefully maintain over time) and to allow for automation over manual effort (the shifting of constraint enforcement from handwritten code to the platform itself).
Automated API generation
Let’s face it: Part of what makes existing apps “plump” as opposed to “lean” is actually developer hubris, including an over-reliance on customization and a sense that everything must be customized. These belief systems fade over time – most developers couldn’t imagine customizing a programming language today, but in the 80’s and 90’s it wasn’t uncommon for companies to maintain large, complex macro and library packages for their custom C coding, all of which were carefully protected as critical, proprietary IP.
Today, API design is often viewed as IP, when in fact many (arguably, most) applications don’t need a highly customized API so much as they need a clear, easily scaled and secured API that works well and evolves safely (see next item).
Automatically generated APIs aren’t just faster, though – automating data-driven APIs enables the infrastructure to also turn them from “dumb pipes” into “smart, ACID systems” that ensure that the data they transport, even when it spans different companies, can be kept consistent and up to date at all times (more on this below).
Automated schema and API migration
Business needs aren’t static, and therefore application data models can’t be “one and done”, either. So while lean apps strive for minimalism in their design, they do need to embrace the reality of a business’s long-term ownership needs, which includes ever-evolving customer, market, and internal demands on the software.
If every such change required rewiring the fundamental structure of the application, it would fail to be lean. (In other words, “leanness” isn’t just about what’s not present on any given day, but also about minimizing effort over the entire lifecycle of an application.) And these updates need to affect APIs in a controlled fashion as well, so that developers (both “server” and “client” side) aren’t constantly in the (undifferentiated) business of inventing, applying, securing, and deploying incremental API enhancements.
Data decentralization and distribution
One of the great ironies of the public cloud is that many of the most business-critical needs are the hardest to develop for.
Building an application that can operate resiliently and safely across multiple regions (with different accounts in each region as a best practice) while also seamlessly ensuring that data shared with business partners is always correct, complete, and up to date is one of the hardest challenges in software systems today. Throw in cross-cloud support and the ability to resiliently remain available when a major cloud provider region goes down and you’re in the ethereal realm of only the most elaborate financial systems and a few mega tech companies…for everyone else, it’s largely a pipe dream today.
Part of making this succeed means shifting the complexity of maintaining ACID transactions into the infrastructure, leaving the application developer with the simpler problem of deciding what data updates have to happen as a single transaction versus separately (since that grouping is an element of the application’s semantics, and can’t be guessed by the infrastructure).
Everything else – cost-optimized cross-cloud data transport, data integrity and security, high-speed replication with ACID properties, etc. – should be handled by the infrastructure.
Built-in access controls and privacy protection
If a company needs to “roll their own” access controls in order to share data with partners, other departments, or different applications, then their infrastructure isn’t working hard enough. These elements should be part and parcel of the data modeling services provided by the application platform.
Ledgering and versioning data
The data model should implicitly support versioning and ledgering of data, rendering the need to manually maintain logs, backups, or audit controls unnecessary.
Cross-cloud
Applications, and application developers, can’t afford to pretend that other clouds don’t exist. Business partners, mergers and acquisitions, and other routine events limit even the most “all in” company from ignoring other cloud vendors apart from their preferred choice.
And increasingly, picking the best-of-breed cloud services means being willing to reach across providers to select different aspects of each. Doing that inevitably requires an application infrastructure that offers cross-cloud data and code capabilities as an intrinsic feature. This stands in sharp contrast to the Kubernetes, “port it to every cloud and run it yourself there” approach, which is costly in terms of time, people, and infrastructure spend, and still results in monocloud silos that are tough to interoperate.
Scalable, pay-per-request, SaaS-style infrastructure
Whether one calls it “serverless”, “fully managed”, “PaaS”, or something else, application infrastructure needs to be as easy to consume, scale, and operate as adding another user to a Slack account. The days of an already overburdened application team being willing to deploy, scale, monitor, and maintain another company’s software are gone forever, and the expectation is clearly that infrastructure should be “adult”, as in, not require babysitting to scale, secure, maintain, or otherwise keep it running as intended.
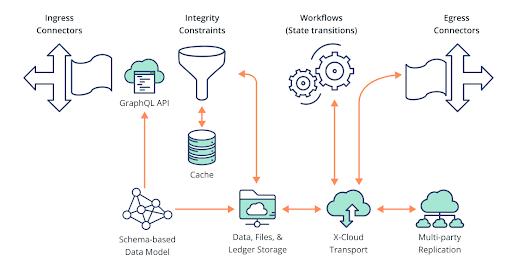
Figure 1: Key capabilities of a lean app that are provided by the platform
An example: Acme Bank
Let’s put all of this together and imagine a simple example based on Acme Bank, which has been a commercial bank in the past but now wants to get into retail banking as well and needs an application to model its new retail banking needs, such as ATM and teller-based deposits and withdrawals for end user checking accounts. We’ll ignore some business details (like savings versus checking accounts) to keep it simple. We start by expressing a very basic data model:
- User_Account(customer:string, balance:number)
We’ll also need to express which cloud providers, regions, and parties need to share the data we modeled above. Let’s say that Acme itself wants to operate in two regions, both on AWS, to satisfy regulations that require fault tolerance in the event of a region-wide outage, but also needs to share data with a regulator who operates in the Azure cloud:
- Acme_East_Region(cloud:AWS, region:us-east-1)
- Acme_West_Region(cloud:AWS, region:us-west-2)
- FINRA(cloud:Azure, region:eastern_us)
Access controls are fairly simple: Acme can read and write balances from either region, but FINRA can only read balances, since it’s just there to ensure compliance with banking laws. We’ll invent some notation for this:
User_Account(read:{Acme_East, Acme_West, FINRA}, write:{Acme_East, Acme_West})
(Note: In a more elaborate example, these settings might need to vary on a per-item basis based on the actual data; here, they’re expressed at a per-node level as part of the overall data schema as partner-level data sharing rules that don’t vary from account to account.)
Then, we add some simple integrity constraints:
- User_Account.balance >= 0
- User_Account.name IS UNIQUE
Because Acme has other systems that need to know about account updates – including legacy systems that run on a mainframe – we also create a simple event hook to notify them of changes our app has processed:
- EventHub.webhook(<mainframe’s API URL>1) And…that’s it. From here, infrastructure can supply everything we need, from ACID-based cross-cloud data replication to crafting GraphQL APIs (that include the ability to group withdrawals and deposits atomically) to automatically crafting and implementing versioning and ledgering APIs (and their implementations) and fully automating auditing capabilities to handling both intra- and inter-region scaling and fault tolerance of the underlying compute and data infrastructure.
Notably, what’s not present is anything related to infrastructure: servers, container images, database deployments, etc.
It’s truly lean – the vast majority of what goes into a typical application is gone, even though this lean application can do many things that even the best and brightest hand-written “conventional” applications can’t do today, including cross-cloud, cross-region, cross-party data sharing with ACID guarantees through APIs that are guaranteed to evolve in a secure and backward-compatible fashion over time.
Of course, this example isn’t reflective of all the real-world needs of an application. In practice, it might need a transformation between an existing web app (“front end”) and the generated GraphQL APIs, custom workflows to look for unusual balances or activity that run overnight as batch processes, additional event handlers to hook up other legacy systems and applications, and so forth.
But the central idea, that much of the manual labor of replicating data and crafting “data APIs” can be removed and replaced with smarter infrastructure solutions, remains. Figure 2 illustrates the architecture of our lean banking app
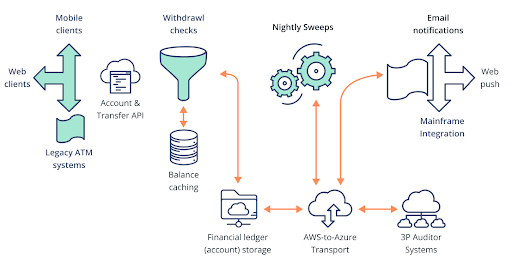
Figure 2: How a lean app for a retail banking solution might look
Are lean apps a new idea?
Of course not – like most changes, the concept of lean apps is just an evolution of what’s come before, weaving established trend lines together and giving a name and strategic direction to inevitable processes that are nascent today, but growing fast.
“Serverless” cloud services, for instance, captured some of the essential ideas of lean apps, but missed out on the idea that the data model is essential to truly simplifying application development.
Cloud-based data lake companies like Snowflake made the leap of treating cross-cloud as a feature, rather than a porting exercise left to the reader a la Kubernetes, but remain focused on specific analytics and BI-based solutions rather than the more general problem of application construction. Cloud-based databases, such as Google’s Spanner, have started down the road of supporting cross-region solutions, but have yet to fully embrace the idea of cross-account (let alone cross-cloud or cross-party) data as a built-in feature.
Blockchains, such as Hyperledger Fabric and Ethereum, embody the idea of distributed data models that can span companies, clouds, and technology stacks, but are missing the scalability, performance, fault tolerance, cloud integration, and application code support that would be necessary to host typical IT business solutions, especially those with serious privacy, compliance, and scalability requirements.
Open source software achieves “zero marginal cost” sharing, but isn’t a solution for delivering SaaS-style operations without manually hosting, scaling, and managing it all. By bringing all these elements together, companies like Vendia make lean apps possible – offering an application framework that enables developers to express, deploy, and operate a lean app today.
Next post – Lean Apps Part 4: The Lean App Manifesto
In the Part 4 of this series, we talk more about the lean app movement and how it can “flip the iceberg” of IT innovation.
Get the whitepaper
If you don’t want to flip through four separate posts, you can download the full white paper here.
Build a lean app
It’s possible to create lean apps today. Companies like Vendia will let you move directly to a lean app methodology for new application development or to layer a significant new feature or capability on top of an existing application. You can get started for free and deploy a sample lean app in less than ten minutes here.
Where wholesale adoption of the idea isn’t (yet) possible, developers and companies still benefit from the concept through incremental steps in various areas of application development. Contact us and we’ll help you learn how to start applying a lean approach to your development today.
About the author
Dr. Tim Wagner, the “Father of Serverless,” is the inventor and leader responsible for bringing AWS Lambda to market. He has also been an operational leader for the largest US-regulated fleet of distributed ledgers while VP at Coinbase, where he oversaw billions in real-time transactions. Dr. Wagner co-founded Vendia with Shruthi Rao in 2020 and serves as its CEO and Chief Product Visionary. Vendia’s mission – to help organizations of all sizes easily share data and build applications that span companies, clouds, and geographies – is his passion, and he speaks and publishes frequently on topics ranging from serverless to distributed ledgers.
t: @timallenwagner
Notes
Footnotes
- If this isn’t a public API, it might require adding a fourth node to enable event delivery through a VPC/VPN integration back into Acme’s on-prem mainframe or other legacy data center systems. ↩